Six agents.
One platform.
TierZero Production Agents handle incidents, alerts, internal questions, CI/CD failures, and reliability risks so your engineers stay in flow.
Hours of digging done in minutes.
When an incident is raised, TierZero joins the channel, investigates across your entire stack, and delivers root cause with receipts while you roll back.
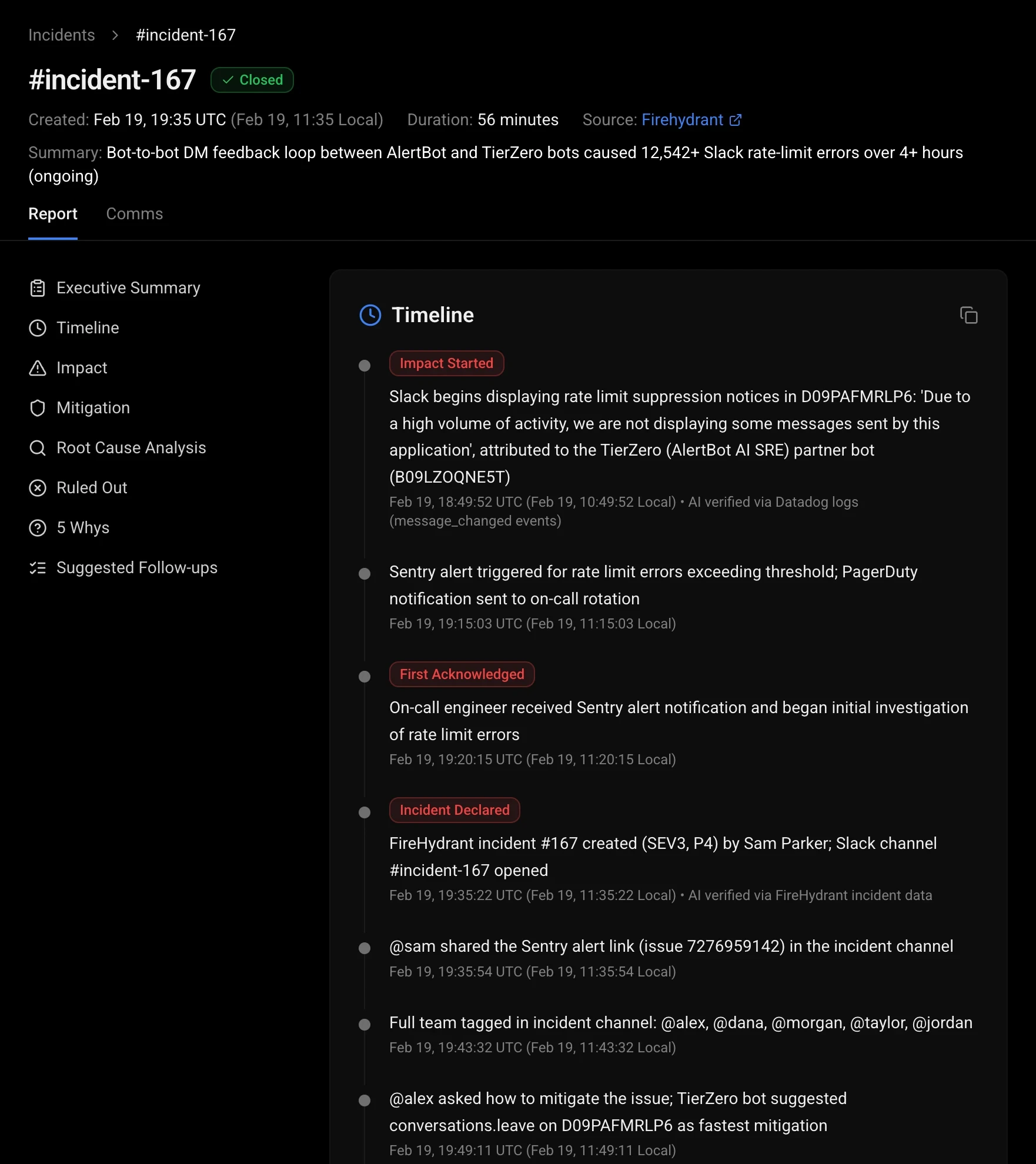
Real-time situation room
Live dashboard with timeline, findings, and charts. Anyone joining the incident gets caught up instantly.
Auto-generated post-mortems
Timeline, impact assessment, action items, and Jira tickets, all drafted from real telemetry.
Automated remediation
Rollback, restart, and feature flag toggle with human-in-the-loop approval.

Every paging alert should matter.
TierZero Alert Agent investigates every alert. Noisy alerts get flagged, related alerts get grouped, and known issues get resolved automatically.
Auto-investigation
Pulls logs, traces, metrics, recent deploys, and past incidents to build a complete picture before an engineer even looks.
Trend analysis
Tracks alert frequency and co-occurrence to surface patterns, like two services that always fail together.
Noise reduction & grouping
Related alerts become one thread. Noisy alerts get flagged for tuning. Your channel stays clean.
Get unblocked instantly.
Engineers ask questions in Slack and get answers grounded in your docs, runbooks, code, past incidents, and live system state in seconds.
Grounded in your stack
Searches Notion, Confluence, runbooks, code repos, past incidents, and live telemetry. Not just docs.
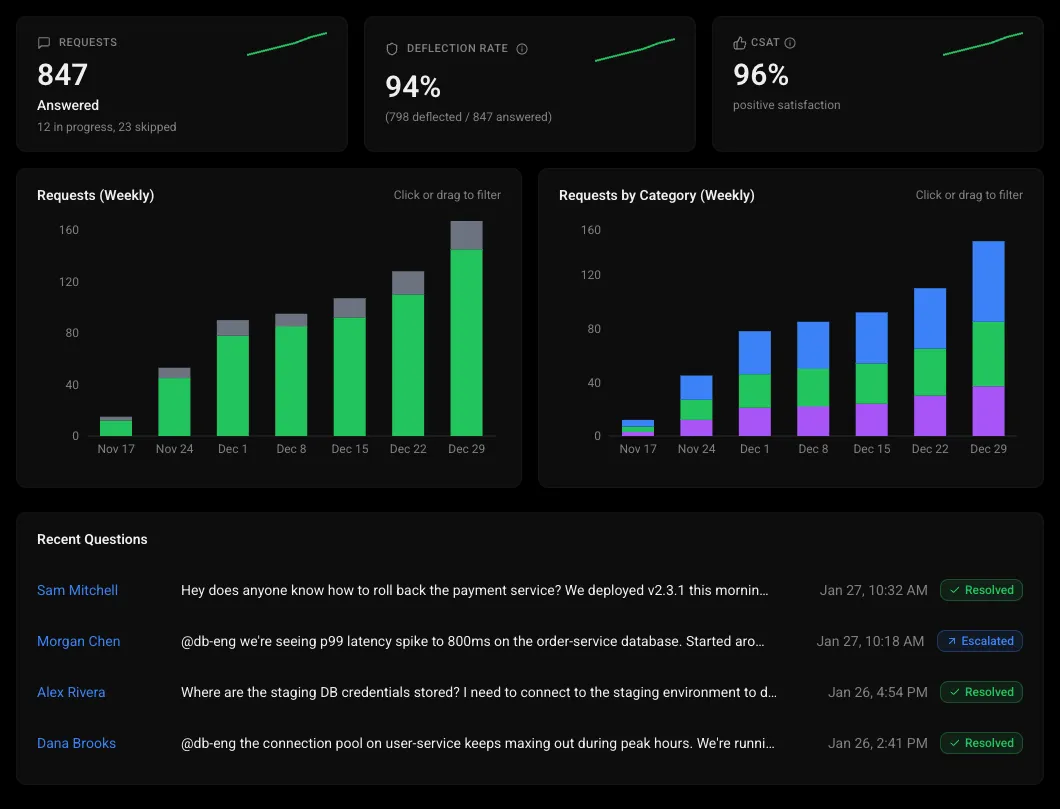
Question analytics & gap detection
Track trending topics, deflection rates, and low-confidence answers to invest in the right documentation.
SOPs from Slack
Restart pods, clear caches, and scale deployments from a Slack message with scoped permissions and audit logging.
The DATABASE_URL environment variable is not set in the CI environment. The test suite attempts to connect to a local PostgreSQL instance which doesn't exist in the CI runner.
Correlated with 3 other failures on this branch in the last 24h, all with the same connection error.
Add DATABASE_URL to the CI environment secrets in .github/workflows/test.yml
CI failures shouldn't break your momentum.
TierZero CI/CD Agent diagnoses build failures, detects flaky tests, and tracks CI health metrics so your team ships instead of debugging pipelines.
Failure diagnosis
Reads build logs, identifies the root cause, and correlates with recent code changes and dependency updates.
Flaky test detection & quarantine
Analyzes pass/fail patterns across hundreds of runs, quarantines flaky tests, and pages the owner.
CI health tracking & fix PRs
Tracks PR merge-to-live time and build success rates. Opens fix PRs when it knows what broke.
Not your grandma's old RAG.
TierZero learns from every incident. A transparent, auditable, self-improving context graph that outperforms RAG on recall, precision, and accuracy.
Multi-source ingestion
Incidents, Slack threads, code reviews, and post-mortems flow in as structured memories with confidence scores and version history.
Graph-powered retrieval
Hybrid search, graph traversal, and investigation replay. +37% recall, +121% precision, +59% accuracy vs RAG.
Fully auditable
Every memory is inspectable, editable, and deletable. Full audit trail for every answer the AI gives.
Backtest against real incidents
Replay any resolved incident against the current agent and compare its root cause to the known answer. Customers see up to 2x accuracy improvement within 2 weeks of corrections.
Your agent gets smarter.
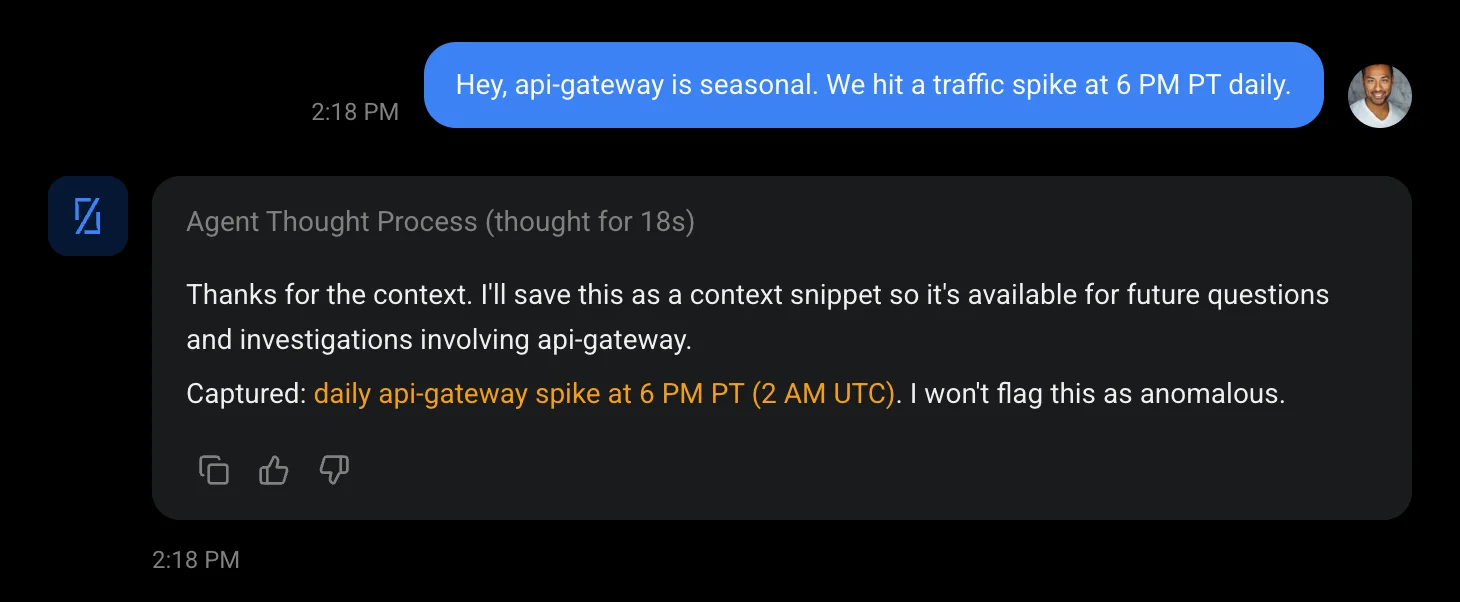
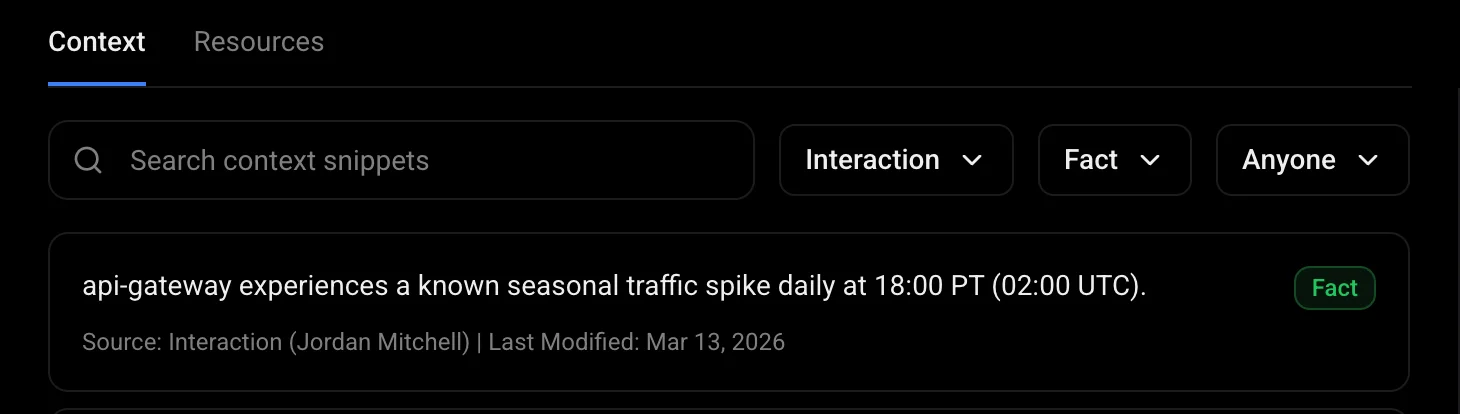
When an engineer corrects the agent, that correction becomes a structured memory in the Context Engine. Next time a similar incident occurs, the agent starts from the corrected understanding, not from scratch.
Corrections are structured, not lost
Every correction becomes a versioned memory record with source attribution, confidence score, and linked services.
Patterns compound across incidents
Investigation playbooks are extracted from past resolutions and replayed when the failure pattern recurs.
Visible and auditable
Every learned memory is inspectable, editable, and deletable. No black-box retraining.
Heap usage growing linearly since deploy v3.8.2. At current rate, OOM kill expected within 4 days. Likely cause: unclosed DB connections in the session refresh path.
P99 latency drifting upward since Jan 28. Trace analysis shows increased time in inventory-check span. Correlated with 18% growth in catalog size — query is not paginated.
Intermittent 503s from Elasticsearch cluster. Node es-data-03 showing elevated GC pauses. Pattern matches pre-incident behavior from INC-892.
Catch it before it catches fire.
TierZero actively scans for reliability risks, performance degradation, and creeping observability costs that no alert would catch.
Slow degradation detection
Catch latency creep and memory leaks before they trigger alerts.
Cost anomalies
Detect unexpected spend increases before they hit your cloud bill.
Pre-deploy risk scoring
Surface high-risk changes based on historical deployment failure patterns.
