Catch it before
it catches fire.
TierZero actively scans for reliability risks, performance degradation, and creeping observability costs that no alert would catch.
Watches what dashboards can't.
Surfaces slow degradation patterns that slip past threshold-based alerts and go unnoticed until something breaks.
Slow degradation detection
Catch latency creep and memory leaks before they trigger alerts.
Cross-service correlation
Individual metrics look fine. Together, they tell a different story.
Historical trend analysis
Compare against baselines from weeks ago, not just hours.
SLO burn rate monitoring
Catch error budget depletion before it breaches your SLO thresholds.
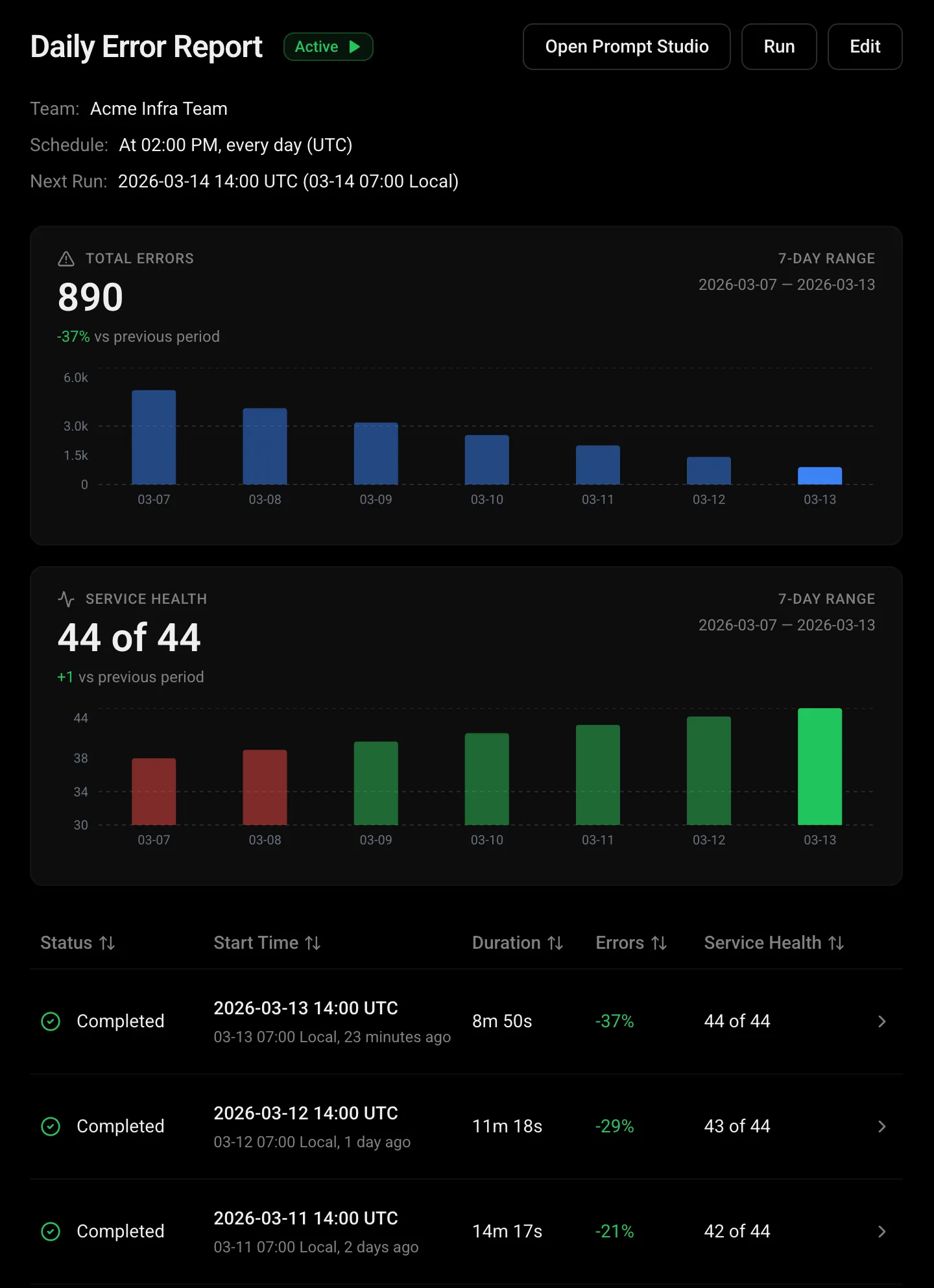
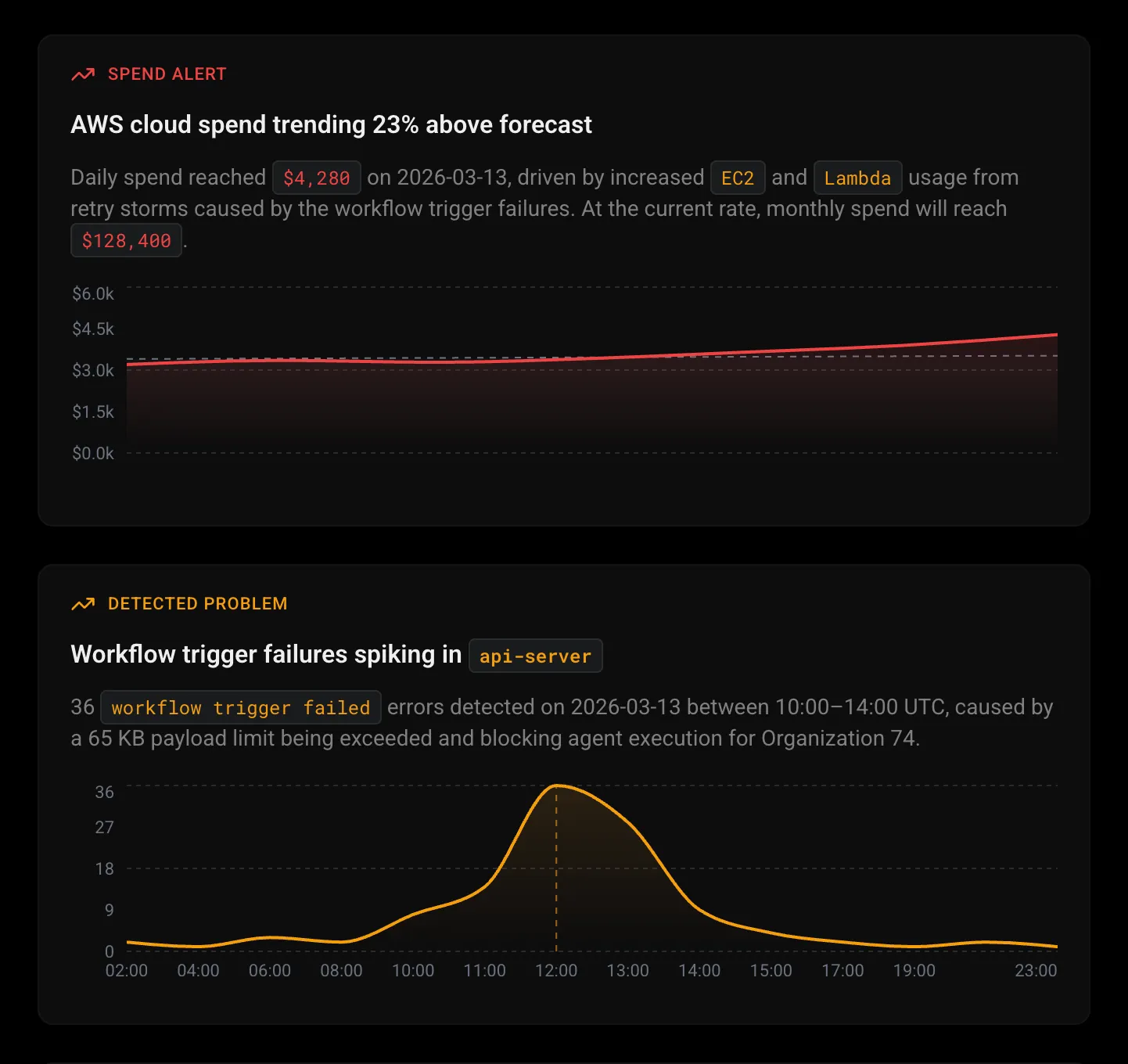
Finds the problem hiding in plain sight.
Detects unusual spend spikes, latency creep, and rising error rates before they compound into outages. Each anomaly comes with context and a suggested next step.
Cost anomalies
Catch unexpected spend increases before they hit your cloud bill.
Performance regression
Surface latency trends and throughput drops — with the commit that caused them.
Error rate analysis
Track error patterns and correlate with deployments and infrastructure changes.
Correlate deploys with degradation.
Correlates recent deploys with performance regression. Identifies which commit introduced latency, error rate spikes, or resource anomalies before they become incidents.
Deploy-correlated regression detection
Automatically links performance degradation to specific deployments and commits.
SLO burn rate monitoring
Catch error budget depletion before it breaches your SLO thresholds.
Pre-merge risk scoring
Surface high-risk changes based on historical deployment failure patterns.
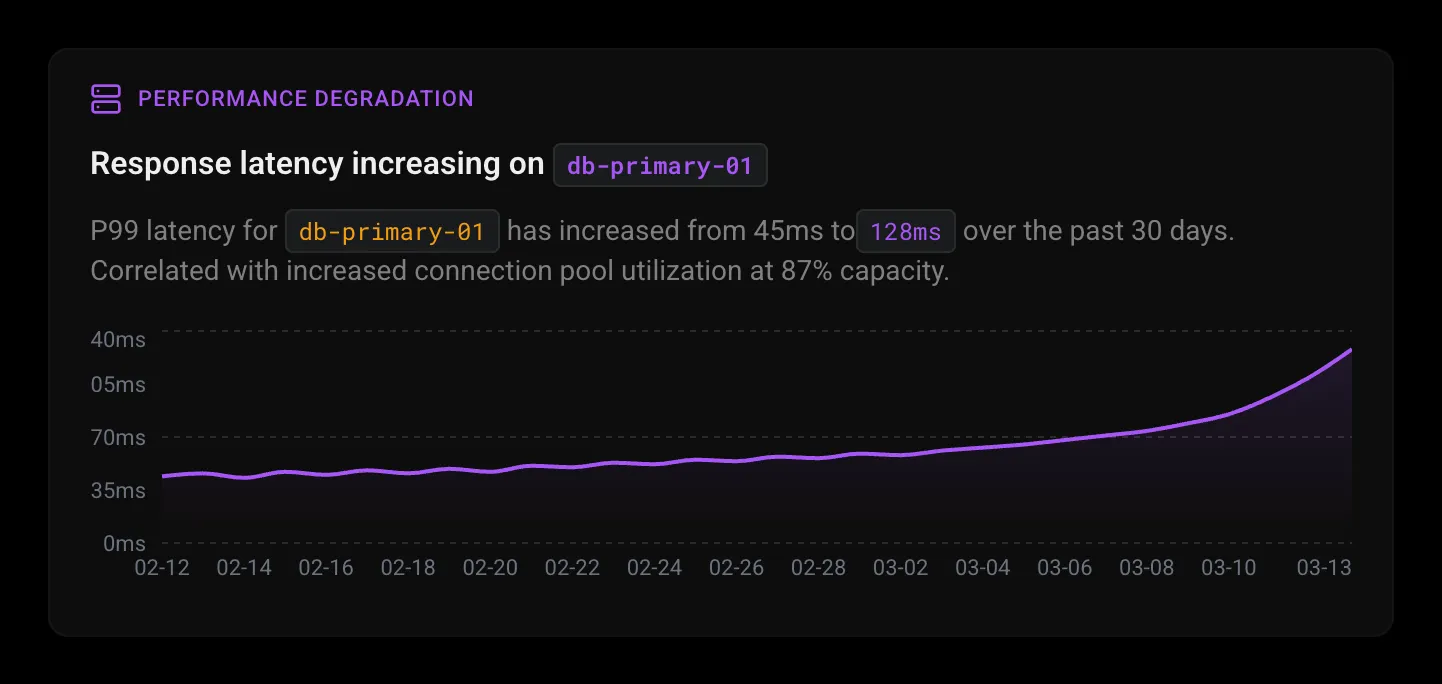
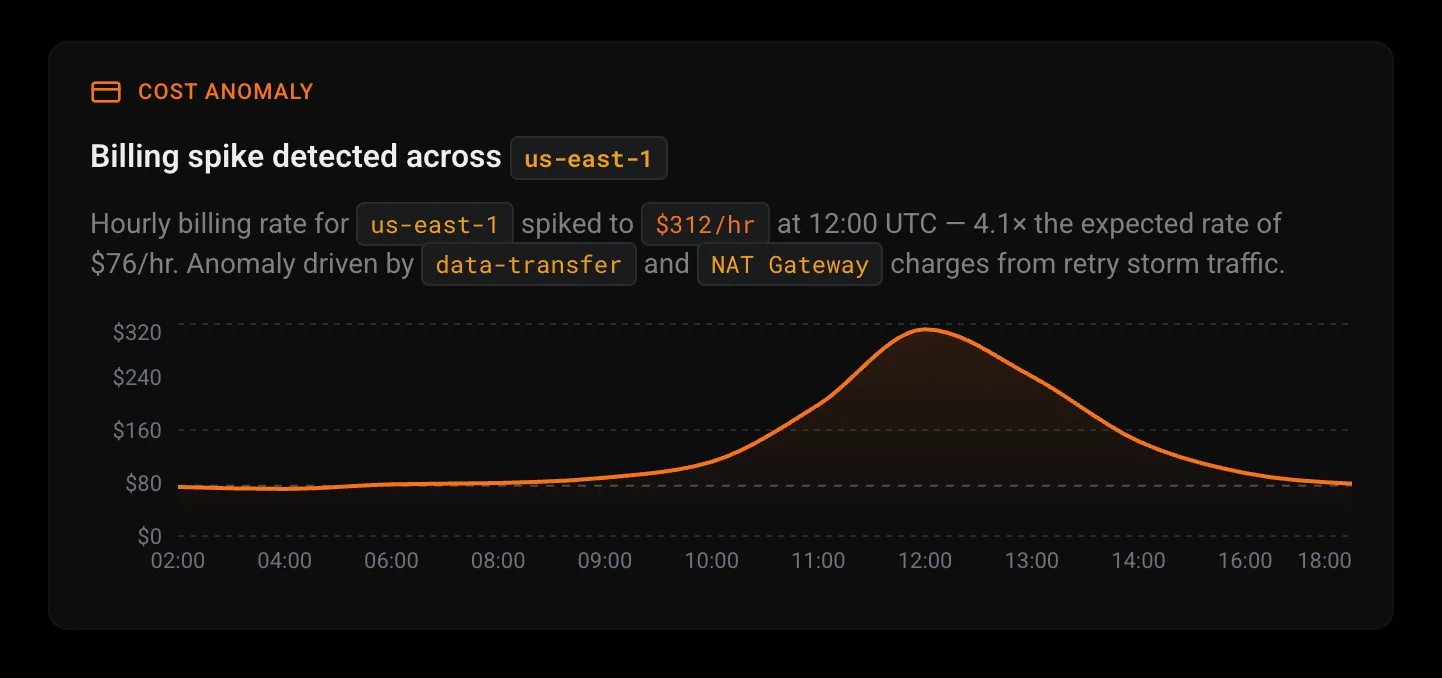
Find the waste your dashboards hide.
Proactive Discovery scans for cost anomalies, billing spikes, and over-provisioned resources across your cloud infrastructure. Surface capacity trends and resource utilization patterns before they become incidents.
Billing anomaly alerts
Detect unexpected cost spikes across cloud providers before they hit your monthly bill.
Resource utilization analysis
Identify over-provisioned and under-utilized resources across your infrastructure.
Auto-scaling policy drift
Detect when scaling policies diverge from actual usage patterns.
Capacity trend monitoring
Surface capacity trends and resource utilization patterns before they become incidents.

Real impact on real infrastructure.
Faster Detection
vs dashboard monitoring