Every paging alert
should matter.
Most don't. TierZero Alert Agent investigates every alert. Noisy alerts get flagged, related alerts get grouped, and known issues get rediscovered.
From alert to resolution
Put TierZero on call
TierZero Alert Agents pick up alerts from PagerDuty, Datadog, Sentry, Opsgenie, or Slack. Every alert gets investigated — not just the ones that page a human.
Context gathered automatically
Investigates alerts across telemetry, recent deploys, related alerts, known issues, and historical patterns. Gathers context so engineers don't have to dig through eight tabs.
Resolve or escalate intelligently
Auto-resolves known issues. Groups related alerts into one thread. Escalates with full context when human judgment is actually needed.
Every alert gets a full investigation — not a glance.
When an alert fires, TierZero doesn't just forward it to Slack. It pulls logs, traces, metrics, recent deploys, and past incidents to build a complete picture. By the time an engineer sees it, the investigation is already done.
Cross-stack correlation
Connects signals across your observability tools, code repos, and deployment pipelines automatically.
Known-issue matching
Checks memory for similar past alerts and applies known fixes without human intervention.
Full context on escalation
When a human is needed, they get the investigation summary — not a raw alert.

An async nightly job (etl-sync-batch) runs at 2:00 AM UTC every night. It opens 200+ database connections simultaneously, exhausting the connection pool and triggering this alert.
123 of 237 fires over the last 30 days occurred within 5 minutes of the job starting. The remaining fires are unrelated and happen at variable times during business hours. This pattern has been consistent since the job was deployed on Dec 2.
Add connection pooling to etl-sync-batch with a max of 20 concurrent connections, or stagger the job into smaller batches to stay under the pool limit.
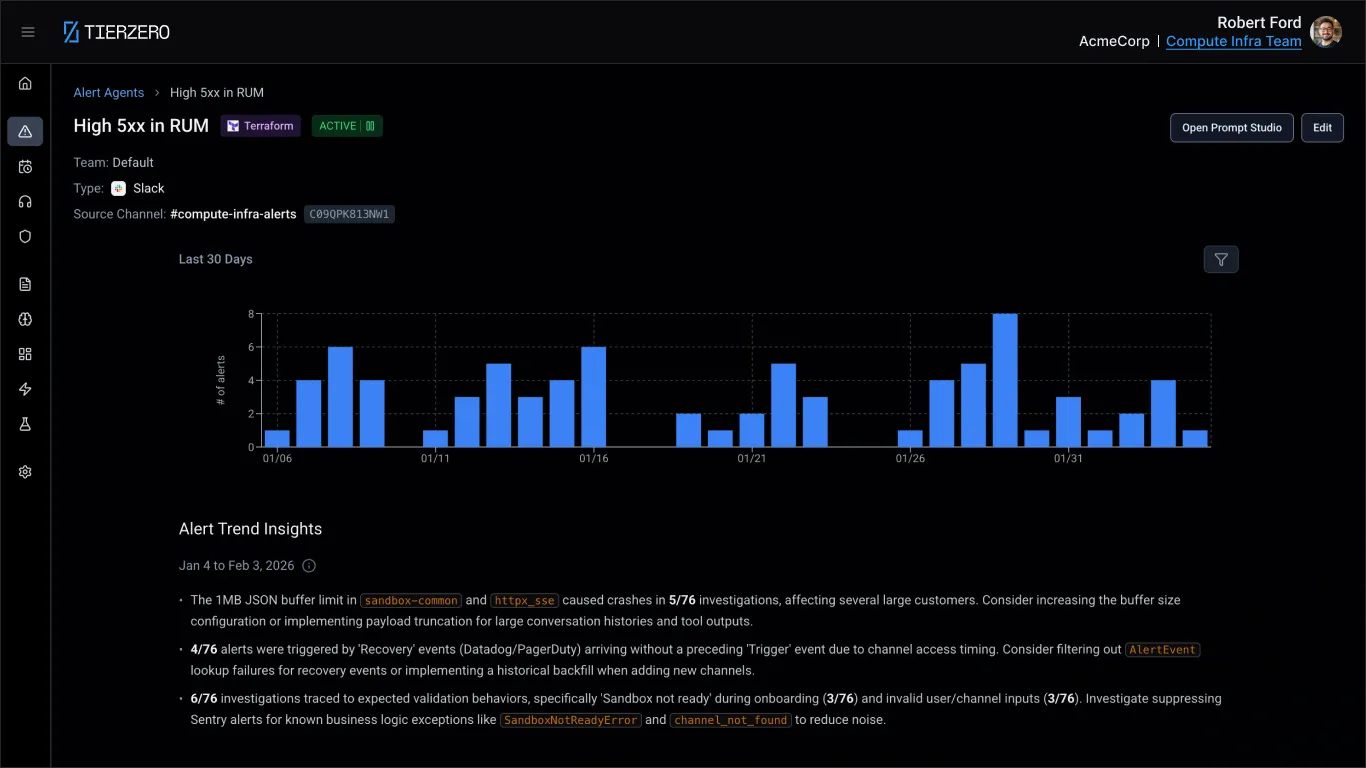
Spot patterns before they become incidents.
TierZero tracks alert frequency, timing, and co-occurrence across your stack. It surfaces trends that humans miss — like an alert that fires 3x more often after Thursday deploys, or two services that always fail together.
Noisy alert detection
Identifies alerts that fire frequently but never lead to action, so you can tune or suppress them.
Correlated failure patterns
Discovers which alerts tend to fire together, revealing shared root causes across services.
Noise reduction is table stakes.
We go deeper.
Noise reduction
Surfaces firing trends and patterns over time, then recommends tuning or suppression so noisy alerts stop reaching your team.
Severity classification
Determines blast radius and severity based on historical patterns, affected services, and downstream impact.
Smart escalation
Integrates with your IDP and escalates with the full investigation context already attached.
Alert grouping
Related alerts become one thread, not ten. Your channel stays clean while the AI handles grouping behind the scenes.
